


Table of Contents
- Introduction
- Editor’s Choice
- AI Training Dataset Market Overview
- Scale of Datasets Utilized in AI Training Across Various Applications
- Data Sources Used by the Public Sector for Training AI Models
- Popular AI Training Dataset Programs
- Sophistication of Organizations’ Analytics Tools in Handling Complex AI-Related Data Sets
- Technical Advancements in AI Training Datasets
Introduction
According to AI Training Dataset Statistics, AI training datasets are essential for developing machine learning models. Containing data that helps the model learn to recognize patterns and make predictions.
These datasets can be categorized into supervised learning, where data includes input-output pairs; and unsupervised learning.
Where only inputs are provided; and reinforcement learning, which involves sequences of actions and rewards.
Key steps in data preparation include cleaning, normalization, and splitting into training, validation, and test sets.
Data can come from real-world sources, be synthetically generated, or be annotated. Challenges include managing biases and ensuring data quality.
Best practices involve using diverse data management, data augmentation, and addressing ethical concerns to create effective and fair AI models.
Editor’s Choice
- The global AI training dataset market revenue reached USD 2.3 billion in 2023.
- By 2032, the market is expected to culminate in a total revenue of USD 11.7 billion. With text datasets contributing USD 4.42 billion, image and video datasets USD 3.79 billion, and audio datasets USD 3.49 billion.
- Various end-use industries significantly influence the global AI training dataset market, each contributing a distinct share to the overall market. The IT and telecommunications sector holds the largest share at 31%. Reflecting its critical role in driving technological advancements and data-centric innovations.
- As of 2020, the IT and telecommunications industry worldwide employed artificial intelligence (AI) across various use cases, each reflecting a significant share of respondents. Cybersecurity emerged as the leading application, with 52% of respondents indicating its usage to enhance security measures against cyber threats.
- For facial recognition technologies, training data encompasses over 450,000 facial images.
- As of October 2022, the public sector in South Korea utilized a variety of data sources for training artificial intelligence (AI) models. The predominant source was in-house data, excluding customer data, which was used by 56.3% of respondents.
- Google’s Open Images dataset offers over 9 million annotated images suitable for various computer vision tasks.
AI Training Dataset Market Overview
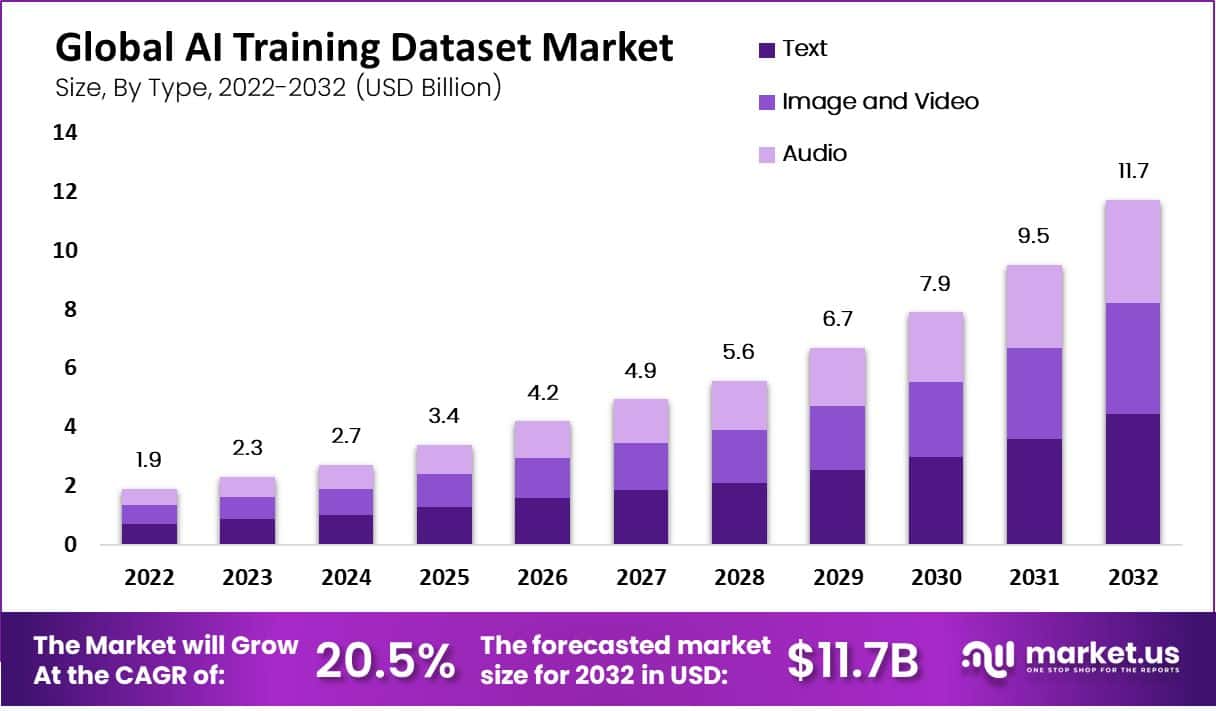
Global AI Training Dataset Market Size
- The global AI training dataset market has demonstrated significant growth over the years at a CAGR of 20.5%. With revenue increasing from USD 1.9 billion in 2022 to USD 2.3 billion in 2023.
- The upward trajectory is projected to persist, with revenues reaching USD 9.5 billion in 2031 and culminating in an impressive USD 11.7 billion by 2032.

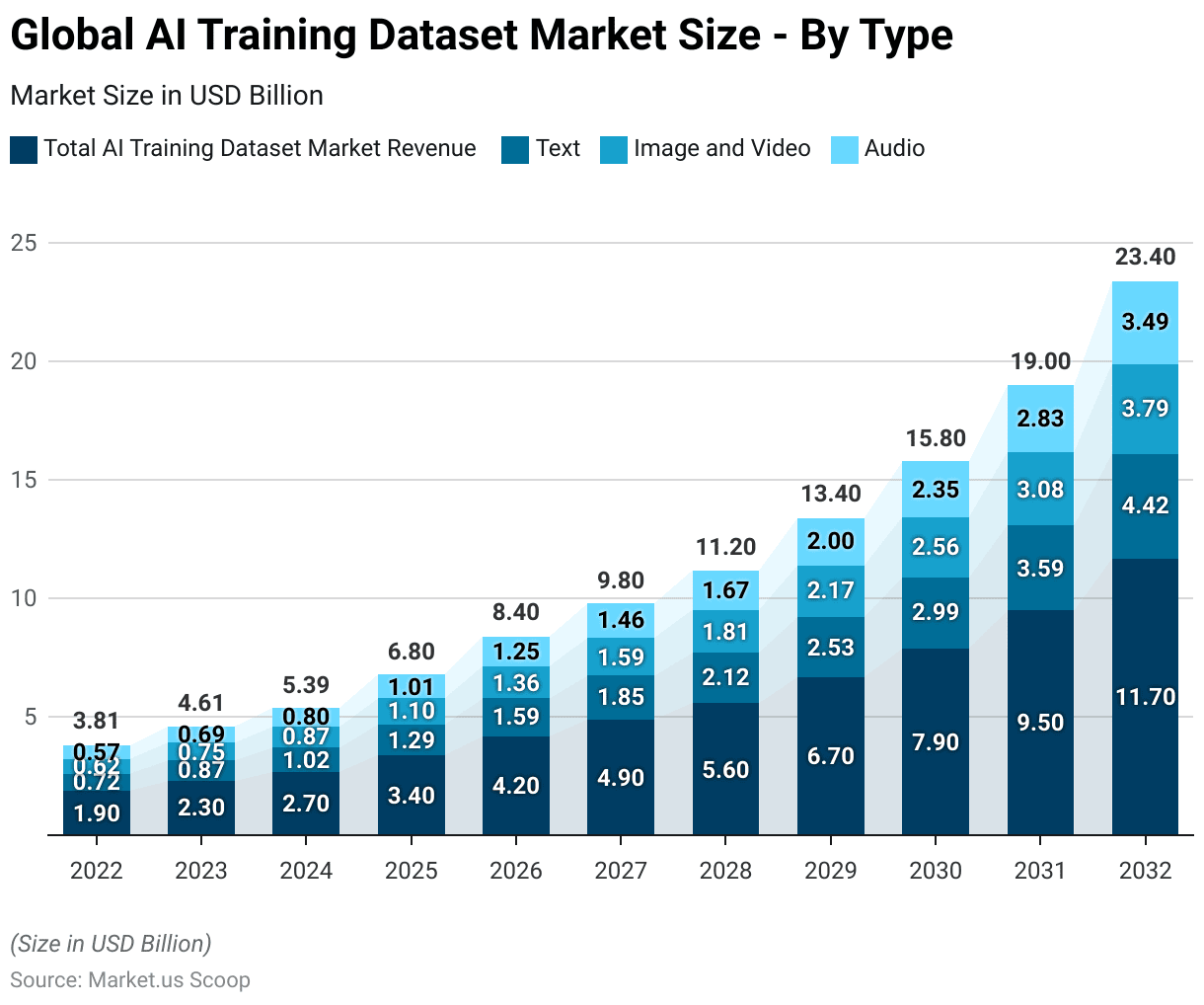
Global AI Training Dataset Market Size – By Type
- The global AI training dataset market, segmented by type, has exhibited robust growth from 2022 to 2027.
- By 2023, the total revenue increased to USD 2.3 billion, with text, image, video, and audio datasets earning USD 0.87 billion, USD 0.75 billion, and USD 0.69 billion, respectively.
- By 2032, the market culminated in a total revenue of USD 11.7 billion. With text datasets contributing USD 4.42 billion, image and video datasets USD 3.79 billion, and audio datasets USD 3.49 billion.
AI Training Dataset Market Share – By End-Use Industry
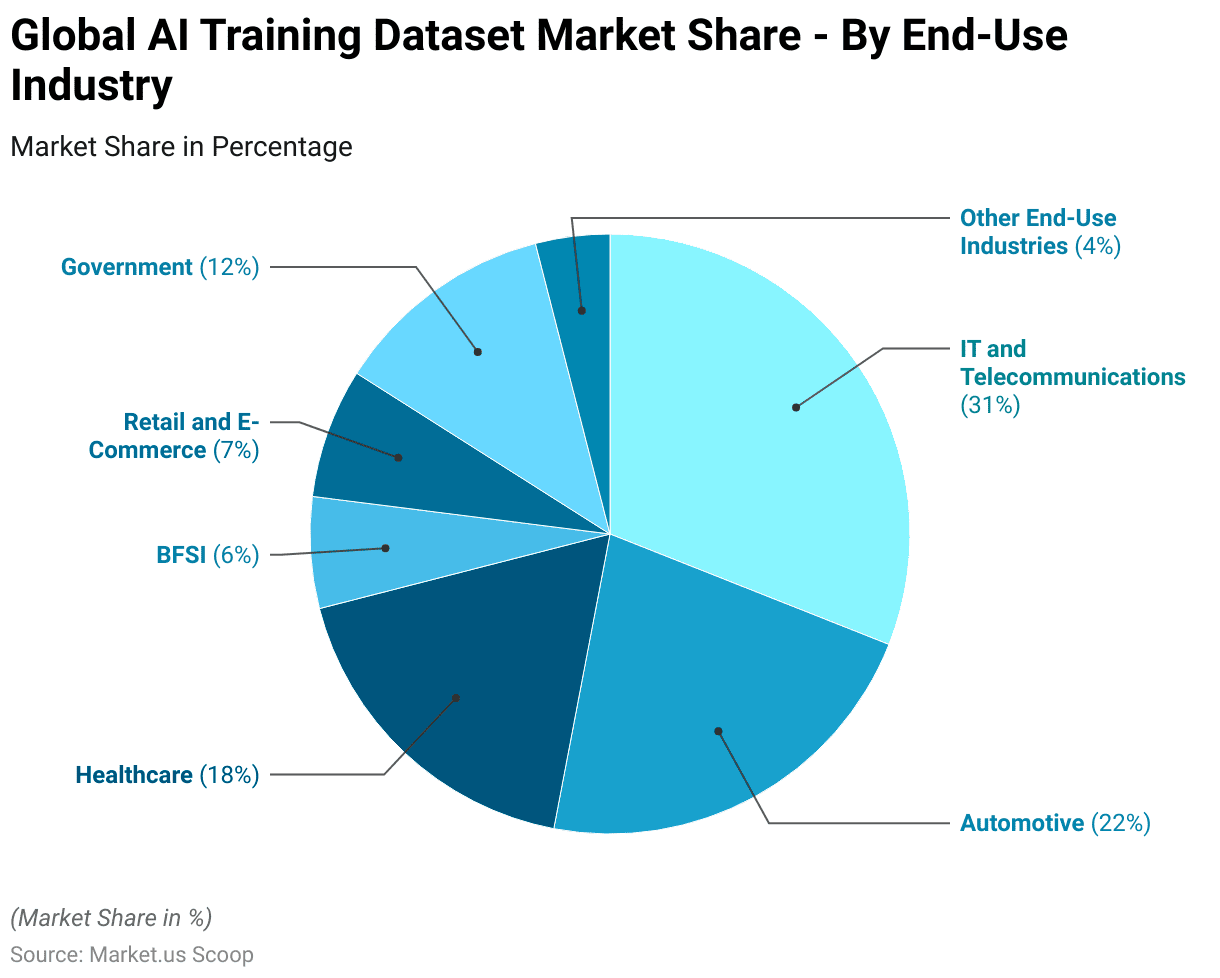
- Various end-use industries significantly influence the global AI training dataset market, each contributing a distinct share to the overall market.
- The IT and telecommunications sector holds the largest share at 31%. Reflecting its critical role in driving technological advancements and data-centric innovations.
- The automotive industry follows with a 22% share, underscoring the growing adoption of AI for autonomous driving and smart vehicle technologies.
- The healthcare sector represents 18% of the market. It demonstrates the increasing integration of AI in medical diagnostics, patient care, and healthcare management.
- The retail and e-commerce industry accounts for 7%. Highlighting the use of AI for personalized shopping experiences and supply chain optimization.
- The government sector, with a 12% share, indicates the implementation of AI for public administration, security, and infrastructure development.
- The banking, financial services, and insurance (BFSI) sector contributes 6%. Showcasing AI’s role in fraud detection, customer service, and financial analytics.
- Other end-use industries, collectively holding 4%, further illustrate the diverse applications and growing penetration of AI training datasets across various sectors.
Scale of Datasets Utilized in AI Training Across Various Applications
- The datasets employed for training artificial intelligence systems vary widely in scale depending on the application.
- For facial recognition technologies, training data encompasses over 450,000 facial images.
- Image annotation efforts involve more than 185,000 images, with close to 650,000 objects annotated within these images.
- Sentiment analysis on platforms like Facebook utilizes a dataset comprising over 9,000 comments and 62,000 posts.
- Chatbot systems are trained on a substantial dataset of approximately 200,000 questions and over 2 million corresponding answers.
- Additionally, translation applications leverage a dataset consisting of over 300,000 audio or speech recordings from non-native speakers.
Data Sources Used by the Public Sector for Training AI Models
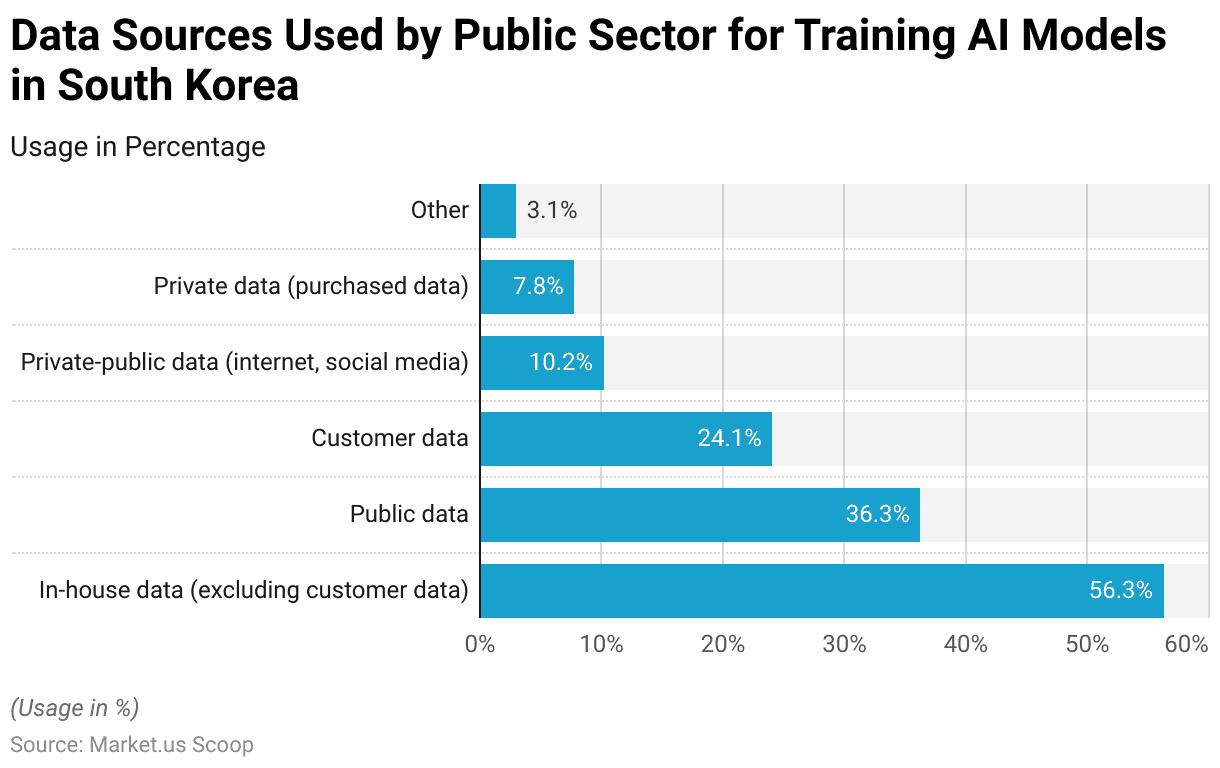
- As of October 2022, the public sector in South Korea utilized a variety of data sources for training artificial intelligence (AI) models.
- The predominant source was in-house data, excluding customer data, which was used by 56.3% of respondents.
- Public data was the next most common source, utilized by 36.3% of respondents.
- Customer data was employed by 24.1% of the respondents, indicating its significant role in AI model training.
- Additionally, private-public data sourced from the internet and social media accounted for 10.2% of usage.
- Private data was purchased by 7.8% of respondents.
- Other data sources were reported by 3.1% of respondents. Reflecting a smaller but notable diversity in data sourcing for AI training within the public sector.
Popular AI Training Dataset Programs
- AI training dataset programs are crucial for developing robust machine learning models.
- Popular programs include Appen, which provides high-quality, diverse datasets across text, audio, image, and video modalities. Leveraging a global workforce of over 1 million to ensure detailed annotation and data quality.
- Google’s Open Images dataset offers over 9 million annotated images suitable for various computer vision tasks.
- Another notable mention is ImageNet, which contains over 14 million images across numerous categories and is widely used for image classification and object detection tasks.
- Companies like OpenAI collaborate with various partners to curate domain-specific datasets. Such as their partnerships for enhancing language models with data from specific languages or industries.
- However, The use of these comprehensive datasets, which can range from financial data provided by Quandl to large-scale video datasets like Kinetics-700, is integral in advancing AI capabilities across different sectors.
Sophistication of Organizations’ Analytics Tools in Handling Complex AI-Related Data Sets
- The sophistication of organizations’ analytics tools in handling complex AI-related datasets varies considerably.
- According to recent data, 24% of respondents rated their analytics tools as excellent in managing these intricate datasets, reflecting a high level of capability and efficiency.
- A significant portion, 43%, considered their tools to be good, indicating robust functionality and performance in most scenarios.
- Meanwhile, 26% of respondents described their tools as fair. Suggesting adequate performance but with room for improvement in handling complex data.
- Lastly, 7% of respondents rated their tools as basic, highlighting minimal capabilities that may hinder effective AI-related data processing.

Technical Advancements in AI Training Datasets
- Recent advancements in AI training datasets have significantly enhanced the efficiency and accuracy of AI models across various applications.
- One notable development is the use of synthetic data generation, spearheaded by companies like NVIDIA and MIT.
- Moreover, NVIDIA’s Nemotron-4 340B model generates synthetic data that mimics real-world characteristics, optimizing data quality and improving the performance of custom AI models.
- This approach has been shown to be highly effective, particularly in scenarios where access to large, diverse, labelled datasets is limited.
- Additionally, MIT’s StableRep+ model, which combines synthetic imagery with language supervision, has achieved superior accuracy and efficiency compared to traditional models, demonstrating that synthetic data can rival or even surpass real data in training efficacy.
Discuss your needs with our analyst
Please share your requirements with more details so our analyst can check if they can solve your problem(s)
