


Table of Contents
Synthetic Data Generation Market Size
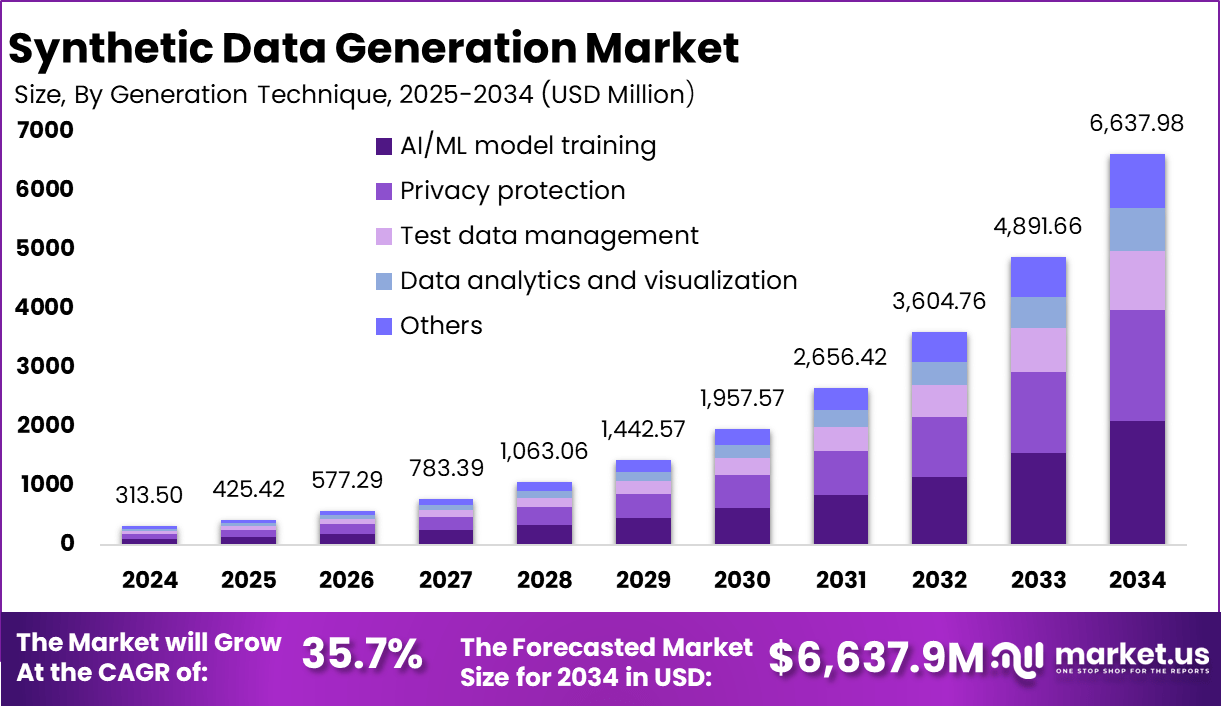
As per the latest insights from Market.us, the Global Synthetic Data Generation Market is set to reach USD 6,637.98 million by 2034, expanding at a CAGR of 35.7% from 2025 to 2034. The market, valued at USD 313.50 million in 2024, is witnessing rapid growth due to rising demand for high-quality, privacy-compliant, and AI-driven data solutions.
North America dominated in 2024, securing over 35% of the market, with revenues surpassing USD 109.7 million. The region’s leadership is fueled by strong investments in artificial intelligence, machine learning, and data security across industries such as healthcare, finance, and autonomous systems. With increasing reliance on synthetic data to enhance AI model training and reduce data privacy risks, the market is poised for significant expansion in the coming years.
Key Takeaways
- The global Synthetic Data Generation market is projected to reach USD 6,637.98 million by 2034, up from USD 313.50 million in 2024.
- The market is expected to expand at a CAGR of 35.7% from 2025 to 2034, driven by the increasing adoption of synthetic data in AI and privacy-sensitive applications.
- In 2024, North America dominated the market, holding over 35% of the total share, with revenues reaching approximately USD 109.7 million.
- The United States led the regional market, valued at USD 112.9 million in 2024, and is forecasted to grow to USD 2,498.3 million by 2034 at a CAGR of 36.3%.
- The Text segment emerged as the leading category in 2024, accounting for over 35.4% of the market share, fueled by its increasing role in AI model training and NLP applications.
- The Fully Synthetic segment held a dominant position in 2024, contributing more than 39% of the market share, as organizations prioritized privacy-preserving data generation.
- The Agent-based system segment accounted for the largest market share in 2024, capturing over 61.7%, driven by its ability to create dynamic, behavior-driven synthetic datasets.
- The AI/ML Model Training segment led the market in 2024, holding over 31.7% of the share, reflecting the growing demand for high-quality synthetic data to improve machine learning models.
- The Healthcare & Life Sciences sector emerged as the top industry for synthetic data generation adoption in 2024, securing over 23.9% of the market share.
Market Overview
Synthetic data generation involves the creation of artificial data that statistically mirrors real-world data, leveraging algorithms and machine learning techniques. This process is essential for scenarios where real data is scarce, sensitive, or needs augmentation to better train machine learning models. The use of synthetic data is particularly advantageous in enhancing data privacy and security, as it allows for the generation of data sets that do not include sensitive or personally identifiable information.
The market for synthetic data generation is witnessing significant growth, driven by its increasing application across various sectors including healthcare, automotive, financial services, and retail. The ability to simulate real-world complexities in data while ensuring compliance with privacy regulations makes synthetic data a critical resource.
The market is expected to grow substantially, reflecting a surge in the adoption of advanced analytics and machine learning, where synthetic data plays a pivotal role in training and developing robust models. This growth is also fueled by the ongoing advancements in generative models like Generative Adversarial Networks (GANs) and Variational Autoencoders (VAEs), which facilitate the creation of highly accurate and diverse synthetic datasets.
The surge in the synthetic data generation market is primarily driven by the critical need for data privacy and the extensive application of machine learning models requiring vast amounts of diverse data. The technology allows organizations to innovate and develop data-driven solutions without the legal and ethical issues associated with real data.
Analysts’ Viewpoint
Demand for synthetic data is robust across sectors that manage sensitive information, such as healthcare, finance, and autonomous driving, where the use of real data can be restrictive or regulated. The ability of synthetic data to replicate complex real-world data scenarios reliably makes it invaluable for training machine learning models and conducting high-stakes simulations.
Given the expansive growth trajectory and the broadening applications of synthetic data, the sector presents significant investment opportunities. Areas such as regulatory compliance, automated decision-making, and customer personalization in marketing are particularly ripe for investments that leverage the capabilities of synthetic data.
Adopting synthetic data generation offers businesses numerous benefits, including reduced costs associated with data management, enhanced data privacy, improved accuracy of AI/ML models, and the capability to scale data operations without ethical or legal concerns. These advantages drive greater operational efficiency and foster innovation without compromising data security.
The regulatory landscape increasingly favors technologies that can provide data utility while ensuring compliance with stringent data protection laws such as GDPR in Europe and CCPA in California. Synthetic data fits well within these frameworks, offering a solution that balances utility with compliance, which is particularly crucial in highly regulated industries like healthcare and finance.
Regional Analysis
The U.S. synthetic data generation market has exhibited substantial growth, valued at USD 112.9 million in 2024, and is anticipated to surge to an estimated USD 2,498.3 million by 2034. This impressive expansion reflects a projected compound annual growth rate (CAGR) of 36.3% from 2025 to 2034. Synthetic data generation involves the creation of artificial data sets that mimic real-world data in structure and statistical properties, which are crucial for training machine learning models when actual data may be limited or sensitive.

In 2024, North America maintained a commanding presence in the synthetic data generation field, securing over 35% of the global market share, with revenues nearing USD 109.7 million. The region’s dominance in this innovative sector can be ascribed to a confluence of strategic factors that have positioned it as a leader in technology adoption and development. The presence of a robust technological infrastructure, coupled with significant investments in artificial intelligence and machine learning, has created a fertile ground for the advancement and implementation of synthetic data technologies.
Moreover, the strong regulatory landscape in North America, particularly in the United States, has played a pivotal role. Regulations concerning data privacy, such as the General Data Protection Regulation (GDPR) and the California Consumer Privacy Act (CCPA), have imposed restrictions on the use of real data. This regulatory environment has driven the demand for synthetic data as a compliant alternative that can bypass legal hurdles, ensuring privacy without compromising on the quality of data used for analytical purposes.

Furthermore, North America’s leading position is reinforced by the concentration of major technology firms and startups that specialize in data science and AI technologies, which continuously push the boundaries of what’s possible in synthetic data generation. These enterprises not only provide the necessary technological expertise but also contribute to the ecosystem by fostering innovation through collaboration and competition. This dynamic environment not only accelerates technological advancements but also facilitates rapid adoption across various industries, from healthcare to finance, where data sensitivity and the need for privacy are paramount.
You May Also Like To Read
- AI in insurance claims processing Market
- North America Edge AI Market
- Emotion AI Market
- Automated Machine Learning Market
Report Scope
| Report Features | Description |
|---|---|
| Market Value (2024) | USD 313.5 Mn |
| Forecast Revenue (2034) | USD 6,637.9 Mn |
| CAGR (2025-2034) | 35.7% |
| Base Year for Estimation | 2024 |
| Historic Period | 2020-2023 |
| Forecast Period | 2025-2034 |
Emerging Trends
- Quality and Control of Data: The sophistication of synthetic data generation tools is increasing, allowing for the creation of highly realistic and controllable datasets. This ensures the synthetic data accurately mirrors real-world conditions.
- Integration with Advanced Technologies: Synthetic data is being increasingly integrated with technologies such as quantum computing and blockchain, enhancing its application across various industries.
- Focus on Privacy and Security: As concerns about data privacy and security grow, the demand for synthetic data, which does not include sensitive real-world information, is also increasing. This trend is particularly prevalent in industries where data privacy is crucial, such as healthcare and finance.
- Domain-Specific Innovations: Companies are focusing on creating synthetic data solutions tailored to specific domains, such as genomics and autonomous vehicles, to provide more precise and useful data.
- Rising Adoption in Emerging Markets: There is a significant increase in the adoption of synthetic data solutions in emerging markets, driven by the need to overcome data scarcity and enhance the accuracy of AI and ML applications.
Top Use Cases
- AI Training and Development: Synthetic data is extensively used to train AI models, especially where real-world data is limited or biased, such as in autonomous driving and healthcare diagnostics.
- Fraud Detection and Risk Assessment: In the financial sector, synthetic data helps in developing models for fraud detection and risk assessments without exposing sensitive customer information.
- Data Privacy and Compliance Testing: Industries subject to strict data protection regulations use synthetic data to test their systems without the risk of exposing sensitive information.
- Medical Research: In healthcare, synthetic data facilitates the development of medical imaging and diagnosis models, ensuring patient privacy is maintained.
- Enhancing Computer Vision Models: Synthetic data is used to develop and refine computer vision models across various applications, including facial recognition technologies and retail consumer behavior analysis.
Attractive Opportunities
- Healthcare Sector Innovation: The need for extensive data sets in training AI for diagnostics, treatment planning, and medical research provides significant opportunities for the application of synthetic data.
- Automotive Industry Advances: With the push towards autonomous vehicles, synthetic data can simulate diverse driving environments and scenarios, which are crucial for training and testing vehicle systems.
- Financial Services Optimization: Synthetic data offers opportunities for the finance sector to enhance algorithmic trading models and comprehensive risk assessment tools without compromising data security.
- Retail and E-commerce Enhancements: By simulating consumer behavior and purchase patterns, synthetic data aids in developing targeted marketing strategies and improving customer engagement.
- Expansion into Emerging Technologies: The integration of synthetic data with new technologies like IoT and blockchain opens up new possibilities for innovation and enhanced data utility across various sectors.
Key Market Segments
By Data Type
- Image & video
- Tabular
- Text
- Others
By Offering
- Fully synthetic
- Partially synthetic
By Generation Technique
- Statistical methods & models
- Rule-based system
- Agent-based system
- Deep learning methods
- Others
By Application
- AI/ML model training
- Privacy protection
- Test data management
- Data analytics and visualization
- Others
By End Use
- BFSI
- Healthcare & life sciences
- Manufacturing
- Technology & telecommunications
- Automotive & transportation
- Others
Top Key Players in the Market
- Synthesis AI
- Statice
- Mostly AI
- YData
- Ekobit d.o.o.
- Hazy
- Kinetic Vision, Inc.
- Kymera-labs
- MDClone
- Neuromation
- TwentyBN
- DataGen Technologies
- Informatica Test Data Management
Discuss your needs with our analyst
Please share your requirements with more details so our analyst can check if they can solve your problem(s)
